A Tutorial for the Go Programming Language — Deutsche Übersetzung
Achtung: Dieses Dokument ist veraltet. Eine zuverlässige Anleitung ist Eine Tour durch Go.
- Das Original:
-
Das Original zu diesem Text wurde kurz vor der Veröffentlichung von Go 1
am 27.3.2012 durch
http://tour.golang.org - A Tour of Go ersetzt.
Es lässt sich aber weiterhin aus dem Mercurial-Repositorium von Go rekonstruieren.
http://golang.org/doc/install/source (hg update weekly.2012-02-22) - Diese Übersetzung:
-
http://www.bitloeffel.de/DOC/golang/go_tutorial_20120222_de.html
Stand: 22.02.2012
© 2010-12 Hans-Werner Heinzen @ Bitloeffel.de
Die Nutzung dieses Dokuments ist unter den Bedingungen von Creative Commons Namensnennung 3.0 erlaubt. Für die verlinkten Quelldateien gelten andere Bestimmungen.
Für die Fachbegriffe gibt es hier noch eine Wörterliste.
Eine Anleitung zum Programmieren in Go
Einleitung
Dies ist eine Einführung in die Grundlagen der Programmiersprache Go. Sie wendet sich an Programmierer, die vertraut sind mit C oder C++. Diese Einführung ist keine erschöpfende — was dem zur Zeit am nächsten kommt, ist die "Language Specification". Nach dieser Einführung sollten Sie sich "Effective Go" anschauen, welches tiefer eintaucht in den Gebrauch der Sprache und sich über Stil und typische Programmiermuster auslässt. Außerdem gibt es einen interaktiven Einführungskurs mit Namen "A Tour on Go".
Um das Charakteristische der Sprache zu zeigen, durchschreiten wir
der Reihe nach mehrere kleine Programme. Allesamt sind sie lauffähig
(jedenfalls waren sie es, als dies hier geschrieben wurde) und im Verzeichnis
/doc/progs/ zu finden.
Hallo, Welt
Fangen wir an, wie üblich:
package main
import fmt "fmt" // Paket für formatierte Ein- und Ausgabe
func main() {
fmt.Printf("Hallo, Welt; oder Καλημέρα κόσμε; oder こんにちは 世界\n")
}
Jede Go-Quelldatei deklariert mit einer package-Anweisung,
zu welchem Paket sie gehört. Sie darf andere Pakete importieren,
um deren Funktionen zu nutzen.
Dieses Programm hier importiert das Paket fmt, um Zugriff
auf unser altbekanntes, nun großgeschriebenes und mit Paketnamen
qualifiziertes fmt.Printf zu bekommen.
Funktionen werden mit dem Schlüsselwort func eingeleitet.
Das Programm startet (nach jedweder Initialisierung)
mit der Funktion main im Paket main.
String-Konstanten können mit UTF-8 kodierte Unicode-Zeichen enthalten. (Es ist sogar so, dass Go-Quelldateien als UTF-8-kodiert definiert sind.)
Die Konvention für Kommentare ist diegleiche wie in C++:
/* ... */
// ...
Zum Thema "Drucken" wird später noch viel mehr zu sagen sein.
Semikolon
Sie haben vielleicht bemerkt, dass in unserem Programm kein Semikolon vorkommt.
In Go entdeckt man es typischerweise nur als Trenner für die Klauseln
von for-Schleifen oder ähnlichen Konstrukten;
man braucht sie nicht nach jeder Anweisung.
Tatsächlich ist es so, dass die formale Sprache Semikola benutzt, ähnlich wie C oder Java, und dass automatisch eins eingefügt wird, wenn ein Zeilenende wie das Ende einer Anweisung aussieht. Man muss es nicht selbst eintippen.
Wie das im Detail gemacht wird, können Sie in der Sprachbeschreibung nachlesen. Für die Praxis genügt es zu wissen, dass man am Zeilenende kein Semikolon braucht. (Es kann aber sein, dass Sie welche einfügen müssen, wenn Sie mehrere Anweisungen pro Zeile schreiben.) Außerdem hilfreich: auch vor einer schließenden geschweiften Klammer ist das Semikolon überflüssig.
Diese Herangehensweise sorgt für sauber aussehenden, semikolonfreien Kode.
Etwas anderes überrascht vielleicht: dass nämlich die öffnende geschweifte Klammer nach
einem Konstrukt wie der if-Anweisung auf derselben Zeile wie das
if stehen muss; ist das nicht der Fall, kann die Übersetzung scheitern
oder es kann zu einem falschen Ergebnis führen.
Die Sprache erzwingt diesen Klammerstil zu einem gewissen Grad.
Kompilieren
Go-Programme werden kompiliert. Zur Zeit gibt es zwei Compiler.
Gccgo ist ein Go-Compiler, der das "Back-end" von GCC benutzt.
Weiterhin gibt es eine Garnitur von Compilern mit jeweils verschiedenen (und seltsamen) Namen
für verschiedene Architekturen:
6g für den 64-Bit x86, 8g für den 32-Bit x86, und andere.
Diese Compiler arbeiten deutlich schneller, generieren aber weniger effizienten Kode
als gccgo. Zur Zeit (Ende 2009) besitzen sie außerdem ein robusteres
Laufzeitsystem, aber gccgo holt auf.
Und so kompilieren und starten wir unser Programm. Mit 6g:
$ 6g helloworld.go # kompilieren; Ausgabe ist helloworld.6
$ 6l helloworld.6 # binden; Ausgabe ist 6.out
$ ./6.out
Hallo, Welt; oder Καλημέρα κόσμε; oder こんにちは 世界
$
Mit gccgo sieht es traditioneller aus:
$ gccgo helloworld.go
$ ./a.out
Hallo, Welt; oder Καλημέρα κόσμε; oder こんにちは 世界
$
Echo
Als nächstes haben wir hier eine Version des Unix-Dienstprogramms echo(1):
package main
import (
"os"
"flag" // Parser für Kommandozeilenparameter
)
var omitNewline = flag.Bool("n", false, "ohne Zeilenvorschub am Ende")
const (
Space = " "
Newline = "\n"
)
func main() {
flag.Parse() // durchsucht die Argumentliste und setzt Schalter
var s string = ""
for i := 0; i < flag.NArg(); i++ {
if i > 0 {
s += Space
}
s += flag.Arg(i)
}
if !*omitNewline {
s += Newline
}
os.Stdout.WriteString(s)
}
Dieses Programm ist zwar kurz aber zeigt einiges Neues. Im vorigen Beispiel
haben wir gesehen, wie func eine Funktion einleitete.
Die Schlüsselworte var, const und type
(hier nicht benutzt) leiten ebenfalls Deklarationen ein.
Merke, dass Deklarationen derselben Art innerhalb von Klammern gruppiert werden können,
jeweils eine Position pro Zeile wie in der import-
und der const-Klausel hier.
Aber das ist nicht zwingend — wir hätten auch sagen können:
const Space = " "
const Newline = "\n"
Das Programm importiert das "os"-Paket,
um auf dessen Variable Stdout
zuzugreifen, die vom Typ *os.File ist.
Die import-Anweisung ist eigentlich eine Deklaration: In ihrer allgemeinen Form,
wie wir sie im Hallo-Welt-Programm benutzt haben, benennt sie die Kennung (fmt),
die man dazu benutzt, um auf Elemente des Pakets,
das aus der Datei ("fmt") importiert
wird, zuzugreifen, die wiederum im aktuellen oder einem Standard-Verzeichnis gefunden wird.
Hier hingegen haben wir den expliziten Namen beim Importieren weggelassen; als Voreinstellung
wird der Name benutzt der durch das importierte Paket definiert ist, was per Konvention
natürlich der Dateiname selbst ist. Unser Hallo-Welt-Programm hätte also nur sagen brauchen:
import "fmt".
Natürlich können Sie Ihre eigenen Import-Namen angeben, aber nötig ist das nur, wenn Namenskonflikte zu lösen sind.
Mit gegebenem os.Stdout können wir seine WriteString-Methode
benutzen um die Zeichenkette zu drucken.
Nachdem wir das flag-Paket importiert haben, benutzen wir eine
var-Deklaration, um eine globale Variable zu erzeugen und zu initialisieren;
diese heißt omitNewline und nimmt den Wert von echos
Schalter -n auf.
Die Variable omitNewline ist vom Typ *bool,
also ein Zeiger auf ein bool.
In main.main durchsuchen wir zunächst die Parameter mit flag.Parse,
und erzeugen dann eine lokale String-Variable für die Ausgabe.
Die Deklaration hat die Form
var s string = ""
und besteht aus den Schlüsselwort var gefolgt vom Variablennamen
gefolgt vom Datentyp gefolgt von einem Gleichheitszeichen und dem Anfangswert der Variablen.
Go versucht, prägnant zu sein, und diese Deklaration kann man kürzen.
Weil ein String-Konstante vom Typ string ist, müssten wir das dem Compiler
nicht extra sagen. Wir könnten schreiben:
var s = ""
oder sogar noch kürzer:
s := ""
Der :=-Operator wird in Go häufig genutzt, um eine Deklaration plus Anfangswert
auszudrücken. Einer findet sich in der for-Klausel auf der nächsten Zeile:
for i := 0; i < flag.NArg(); i++ {
Das flag-Paket hat die Parameter durchsucht und hält die, die keine Schalter sind,
in einer Liste bereit, über die in naheliegender Weise iteriert werden kann.
Die for-Anweisung in Go unterscheidet sich gleich mehrfach von der in C.
Erstens ist sie das einzige Schleifenkonstrukt —
es gibt kein while oder do.
Zweitens hat die Klausel keine runden Klammern aber die geschweiften Klammern
um den Rumpf sind obligatorisch.
Das gilt auch für die if- und die switch-Anweisung.
Spätere Beispiele werden zeigen, wie die for-Schreibweise variiert werden kann.
Der Schleifenrumpf erzeugt die Zeichenkette s, indem
er mit += die Parameter und Zwischenräume angehängt.
Wenn -n nicht gesetzt ist, kommt ans Ende noch ein Zeilenvorschub.
Schließlich wird das Ergebnis ausgegeben.
Beachten Sie: main.main ist eine Funktion ohne Parameter
und ohne Rückgabewert. Sie ist so definiert.
Wird das Ende von main.main erreicht, heißt das: Erfolg!
Wollen Sie einen Fehler melden, rufen Sie:
os.Exit(1)
Im os-Paket gibt's weitere wichtige Sachen für den Programmanfang.
Zum Beispiel ist os.Args ein Slice (Abschnitt), das vom
flag-Paket benutzt wird, um an die Kommandozeilen-Parameter zu kommen.
Zwischenspiel: Datentypen
Go hat vertraute Datentypen wie int und uint (also int
ohne Vorzeichen), die ihre Werte in "maschinen-angemessener" Größe darstellen.
Go definiert aber auch Typen mit expliziter Größenangabe wie
int8, float64 und so weiter, außerdem Ganzzahlen ohne Vorzeichen
wie uint, uint32 usw. Dies sind alles eigene Datentypen —
selbst wenn int und int32 beide 32 Bit lang sind,
sind sie nicht vom selben Typ. Es gibt auch den Typ byte, synonym zu
int8, welches der Elementtyp für Strings ist.
Fließkommatypen geben immer ihre Größe an: float32 und float64,
sowie complex64 (zwei float32s) und complex128
(zwei float64s). Komplexe Zahlen werden in dieser Einführung nicht behandelt.
Apropos, string ist ebenfalls ein integrierter Datentyp.
Strings-Werte sind unveränderlich — sie sind nicht einfach nur
byte-Arrays.
Ein String-Wert, einmal erzeugt, kann nicht mehr verändert werden.
Aber natürlich können Sie String-Variablen ändern, einfach durch eine neue Zuweisung.
Dieser Schnipsel aus strings.go ist gültiger Kode:
s := "hello"
if s[1] != 'e' {
os.Exit(1)
}
s = "good bye"
var p *string = &s
*p = "ciao"
Dagegen sind folgende Anweisungen ungültig, weil sie String-Werte verändern würden:
s[0] = 'x'
(*p)[1] = 'y'
Go-Strings ähneln den const strings in der C++-Welt, während der Zeiger
auf einen String das Analogon zu einer const string-Referenz ist.
Ja, es gibt Zeiger. Indes, Go vereinfacht ihren Gebrauch — lesen Sie weiter.
Arrays werden so definiert:
var arrayOfInt [10]int
Arrays sind Werte, wie Strings auch, aber sie sind änderbar.
Das ist ein Unterschied zu C, wo arrayOfInt als Zeiger zu einem
int-Wert benutzt werden kann.
Weil Go-Arrays Werte sind, ist es sinnvoll (und nützlich) über Zeiger zu Arrays
zu sprechen.
Die Größe eines Arrays ist Bestandteil seines Typs; man kann eine
slice-Variable deklarieren, um eine Referenz auf ein beliebiges Array
beliebiger Größe aber mit demgleichen Elementtyp aufzunehmen.
Ein slice-Ausdruck hat die Form a[low : high] und steht für
ein internes Array, das von low bis high -1 indiziert
ist; das Slice selbst wird von 0 bis high-low-1
indiziert. Kurz:
Slices sind Arrays sehr ähnlich, haben aber keine explizite Größe
([] gegenüber [10]); ein Slice ist eine Referenz auf
einen Ausschnitt eines darunterliegenden, üblicherweise anonymen, echten Arrays.
Mehrere Slices können sich Daten teilen, wenn sie Teile desselben Arrays
repräsentieren — Arrays können das nicht!
Slices sind in Go-Programmen weit üblicher als echte Arrays; sie sind flexibler, sie sind semantisch gesehen Referenzen und sie sind effizient. Was ihnen fehlt, ist die Kontrolle über das Speicherlayout, wie sie das echte Array hat; wenn Sie genau hundert Elemente eines Arrays in Ihrer Struktur haben wollen, nehmen Sie ein Array! Zum Erzeugen benutzen Sie einen Verbundkonstruktor — der setzt sich zusammen aus einem Typ und, darauf folgend, einem Ausdruck in geschweiften Klammern, zum Beispiel:
[3]int{1,2,3}
Dieser Konstruktor erzeugt ein Array mit 3 Ganzzahlen.
Um ein Array an eine Funktion zu übergeben, werden sie den formalen Parameter fast immer
als Slice deklarieren wollen. Für den Funktionsaufruf schneiden sie das Array auf, um
daraus (effizient) eine Slice-Referenz zu erzeugen, und übergeben Sie diese.
Vorgabe ist, dass obere und untere Grenze eines Slice auch diejenigen des Objekts sind;
also erhält man mit der prägnanten Schreibweise [:] das komplette Array als Slice.
Mit Slices kann man eine Funktion so schreiben (aus sum.go):
func sum(a []int) int { // gibt ein int zurück
s := 0
for i := 0; i < len(a); i++ {
s += a[i]
}
return s
}
Schauen Sie, wie der Rückgabetyp (int) für sum
definiert wird: hinter der Parameterliste.
Um die Funktion aufzurufen, schneiden wir das Array auf. Folgender Aufruf
— wir zeigen bald, wie es einfacher geht — konstruiert ein Array und schneidet es auf:
x := [3]int{1,2,3}
s := sum(x[:])
Wenn Sie ein echtes Array erzeugen, und der Compiler soll für Sie die Elemente zählen,
dann benutzen Sie ... als Array-Größe:
x := [...]int{1,2,3}
s := sum(x[:])
So penibel braucht man aber nicht sein. In der Praxis aber, solange Sie es es nicht besonders genau mit dem Layout Ihrer Datenstruktur nehmen, ist ein Slice — leere eckige Klammern ohne Größenangabe — alles, was Sie brauchen:
s := sum([]int{1,2,3})
Desweiteren gibt es Maps, die so initialisiert werden können:
m := map[string]int{"eins":1 , "zwei":2}
Die integrierte Funktion len, die die Anzahl der Elemente liefert,
erschien uns zuerst in sum. Sie funktioniert mit Strings, Arrays, Slices,
Maps und Channels.
Was ebenfalls mit Strings, Arrays, Slices, Maps und Channels funktioniert, ist die
range-Klausel in for-Schleifen. Statt mit:
for i := 0; i < len(a); i++ { ... }
über die Elemente eines Slices (oder einer Map oder ...) zu iterieren, können wir schreiben:
for i, v := range a { ... }
Das weist i den Index und v den Wert des jeweiligen
Elements des Zielbereichs zu. Mehr Anwendungsbeispiele gibt's in
Effective Go.
Zwischenspiel: Speicherzuteilung
Die meisten Datentypen in Go sind Werte. Ob int oder struct
oder Array, jede Zuweisung kopiert den Inhalt des Objekts.
Um Speicher für eine neue Variable zu reservieren, benutzen Sie die integrierte Funktion
new, welche einen Zeiger auf den zugeteilten Speicher zurückgibt:
type T struct { a, b int }
var t *T = new(T)
oder Go-typischer:
t := new(T)
Einige Datentypen — Maps, Slices und Channels (siehe unten) — sind, semantisch gesehen,
Referenzen. Wenn Sie den Inhalt eines Slice oder einer Map ändern, sind auch die anderen
Variablen, die dieselben Daten referenzieren, von der Änderung betroffen.
Für diese drei Datentypen benutzen Sie die integrierte Funktion make:
m := make(map[string]int)
Diese Anweisung initialisiert eine neue Map, bereit mit Inhalt gefüllt zu werden, wohingegen die Deklaration:
var m map[string]int
nur eine nil-Referenz erzeugt, die nichts enthält.
Um die Map nutzen zu können, müssen Sie die Referenz mit make oder
durch Zuweisung aus einer bestehenden Map erst initialisieren.
Beachten Sie, dass new(T) den Typ *T,
aber make(T) den Typ T zurückgibt.
Wenn Sie (versehentlich) ein Referenz-Objekt mit new reservieren,
bekommen Sie einen Zeiger auf eine nil-Referenz zurück, was dasgleiche wäre
wie das Deklarieren einer nicht initialisierten Variablen, von der Sie dann
die Adresse benutzen wollten.
Zwischenspiel: Konstanten
Wenn auch Ganzzahlen in Go in vielen Größen daherkommen, so gilt das nicht für
Integer-Konstanten. Es gibt keine Konstanten wie 0LL oder 0x0UL.
Satt dessen werden Integer-Konstanten als Werte hoher Genauigkeit behandelt;
ein Wert kann nur überlaufen, wenn er einer Integer-Variablen zugewiesen werden, die zu klein
ist, um ihn aufnehmen zu können.
const hardEight = (1 << 100) >> 97 // erlaubt
Manche Feinheiten würden den Verweis auf das Juristen-Englisch der "Sprachbeschreibung" verdienen; hier sollen ein paar kommentierte Beispiele genügen:
var a uint64 = 0 // a ist vom Typ uint64, Wert 0
a := uint64(0) // äquivalent; benutzt eine "Konvertierung"
i := 0x1234 // i kriegt den Vorgabe-Typ: int
var j int = 1e6 // erlaubt - 1000000 kann durch int dargestellt werden
x := 1.5 // float64, die Voreinstellung für Fließkommazahlen
i3div2 := 3/2 // Ganzzahldivision - Ergebnis ist 1
f3div2 := 3./2. // Fließkommadivision - Ergebnis ist 1.5
Konvertieren funktioniert nur in einfachen Fällen, wie das Konvertieren von
ints verschiedener Größen mit oder ohne Vorzeichen, und zwischen
ints und Fließkommazahlen, und in einigen anderen hier nicht genannten Fällen.
Es gibt es keine automatische Zahlenkonvertierung in Go außer, wenn Konstanten
während der Zuweisung zu einer Variablen konkrete Größe und konkreten Typ bekommen.
Ein I/O-Paket
Als nächstes schauen wir uns ein einfaches Paket für Datei-Ein/Ausgaben unter Unix an.
Dieses hat eine Open/Close/Read/Write-Schnittstelle und der Kode in
file.go beginnt so:
package file
import (
"os"
"syscall"
)
type File struct {
fd int // Dateinummer (Deskriptor), intern
name string // Dateiname fürs Open
}
Die ersten Zeilen vereinbaren den Paketnamen file,
und importieren dann zwei weitere Pakete. Das os-Paket versteckt die
Unterschiede verschiedener Betriebssysteme und erlaubt eine konsistente Sicht auf
Dateien und anderes; hier werden wir seine Werkzeuge zur Fehlerbehandlung nutzen
sowie den Kern der Datei-Ein/Ausgabe.
Als nächstes haben wir das niedriger angesiedelte syscall-Paket,
das wiederum eine einfache Schnittstelle zu den darunter liegenden Systemaufrufen anbietet.
Dieses Paket ist sehr systemabhängig, und so, wie wir es hier verwenden wollen,
funktioniert es nur auf Unix-artigen Systemen. Die Grundideen aber sind allgemeiner gültig.
(Eine Windows-Version steht unter
file_windows.go
bereit.)
Das nächste ist eine Typdefinition: das Schlüsselwort type leitet eine
Typdeklaration ein, in diesem Fall für eine Datenstruktur mit Namen File.
Und, um's ein bischen interessanter zu machen, enthält unser File
den Dateinamen auf den die Dateinummer deutet.
Weil File mit einem Großbuchstaben beginnt, steht dieser Typ auch außerhalb
des Pakets zur Verfügung, d.h. für die Nutzer des Pakets. Die Regel für Sichtbarkeit von
Informationen in Go ist simpel: Wenn der Name (eines "top-level"-Typs, einer Funktion oder
Methode, einer Konstanten oder Variablen, eines Strukturfelds oder einer Strukturmethode)
mit einem Großbuchstaben beginnt, können Paketnutzer ihn sehen.
Wenn nicht sind Name und das damit bezeichnete Ding nur
innerhalb des Paket sichtbar, in dem sie deklariert sind. Das ist mehr als eine Konvention:
die Regel wird durch den Compiler erzwungen. In Go benutzen wir für öffentlich sichtbare
Namen den Begriff "exportiert".
In File beginnen alle Feldnamen mit Kleinbuchstaben, sind also unsichtbar
für die Benutzer, aber wir werden gleich ein paar exportierte, großgeschriebene Methoden
hinzufügen.
Zunächst aber noch eine Fabrikmethode, um ein File zu erzeugen:
func newFile(fd int, name string) *File {
if fd < 0 {
return nil
}
return &File{fd, name}
}
Diese gibt einen Zeiger auf die neue File-Struktur zurück,
Dateinummer und -name gefüllt. Der Kode nutzt die Idee eines "zusammengesetzten Literals",
wie sie in Go auch für Maps und Arrays gebraucht werden, zur Konstruktion eines neuen Objekts
im Heap-Speicher. Wir hätten auch schreiben können:
n := new(File)
n.fd = fd
n.name = name
return n
aber für eine so simple Struktur wie File ist es einfacher, die Adresse
eines zusammengesetzten Literals zu retournieren, wie das im
return-Befehl von newFile geschieht.
Die Fabrikmethode benutzen wir, um ein paar altbekannte "exportierte" Variablen
vom Typ *File zu konstruieren:
var (
Stdin = newFile(syscall.Stdin, "/dev/stdin")
Stdout = newFile(syscall.Stdout, "/dev/stdout")
Stderr = newFile(syscall.Stderr, "/dev/stderr")
)
Die Funktion newFile wurde nicht exportiert, weil sie eine interne ist.
Korrekterweise benutzt man die exportierte Fabrikmethode OpenFile
(diesen Namen erklären wir in Kürze):
func OpenFile(name string, mode int, perm uint32) (file *File, err error) {
r, err := syscall.Open(name, mode, perm)
return newFile(r, name), err
}
Auf diesen wenigen Zeilen gibt es wieder einiges Neue zu entdecken.
Einmal gibt OpenFile mehrere Werte zurück, eine Datei und einen
Fehler (davon gleich mehr). Wir deklarieren die mehrfachen Rückgabewerte in einer geklammerten
Deklarationsliste; der Syntax nach schauen sie aus wie eine zweite Parameterliste.
Die Funktion syscall.Open gibt ebenfalls mehrere Werte zurück, die wir mit
einer Mehrfach-Variablen-Deklaration abgreifen; für die zwei Werte werden
r und e deklariert, beide vom Typ int (auch wenn
man erst im syscall-Paket nachschauen müsste, um das sehen zu können).
Schließlich gibt OpenFile zwei Werte zurück:
einen Zeiger auf das neue File und einen Fehler.
Wenn syscall.Open scheitert, ist die Dateinummer negativ und
newFile gibt nil zurück.
Nun zu Fehlern: Go besitzt auch ein eigenes, allgemeines Fehlerkonzept:
einen vordefinierten Typ error mit Eigenschaften, die ihn zu einer guten
Grundlage für Fehlerbehandlung machen. (Die Eigenschaften werden weiter unten beschrieben.)
Es ist ratsam, seine Möglichkeiten in der eigenen Schnittstelle zu nutzen,
damit die Fehlerbehandlung im gesamten Go-Kode konsistent bleibt — wir tun es hier auch.
In Open benutzen wir eine Konversion, um den Unix-Integerwert errno
in einen Integertyp os.Errno zu stecken, der error implementiert.
Warum aber heißt es OpenFile und nicht Open? Nun, wir richten uns
nach dem os-Paket von Go, das wir hier als Übung nachbilden.
Das os-Paket nutzt seine Chance und macht aus den am weitesten verbreiteten
Anwendungsfällen — Öffnen zum Lesen , Anlegen zum Schreiben — die einfachsten:
Open und Create. OpenFile hingegen ist der allgemeine
Fall, analog zum Unix-Systemaufruf Open.
Hier nun die Implementierungen für unser Open und unser Create;
sie sind einfach Hüllen, die häufige Fehler vermeiden helfen, indem Sie sich um die verzwickten
Standardargumente kümmern,
fürs Öffnen und — insbesondere — fürs Anlegen einer Datei:
const (
O_RDONLY = syscall.O_RDONLY
O_RDWR = syscall.O_RDWR
O_CREATE = syscall.O_CREAT
O_TRUNC = syscall.O_TRUNC
)
func Open(name string) (file *File, err error) {
return OpenFile(name, O_RDONLY, 0)
}
func Create(name string) (file *File, err error) {
return OpenFile(name, O_RDWR|O_CREATE|O_TRUNC, 0666)
}
Zurück zum eigentlichen Thema.
Jetzt, wo wir Files erzeugen können, können wir auch Methoden für sie schreiben.
Um eine Typmethode zu deklarieren, definieren wir eine Funktion mit einem Empfänger des
gewünschten Typs in Klammern vor dem Funktionsnamen. Hier ein paar Methoden für
*File, für die jeweils eine Empfängervariable file deklariert wird.
func (file *File) Close() error {
if file == nil {
return os.ErrInvalid
}
err := syscall.Close(file.fd)
file.fd = -1 // damit nicht nochmal geschlossen werden kann
return err
}
func (file *File) Read(b []byte) (ret int, err error) {
if file == nil {
return -1, os.ErrInvalid
}
r, err := syscall.Read(file.fd, b)
return int(r), err
}
func (file *File) Write(b []byte) (ret int, err error) {
if file == nil {
return -1, os.ErrInvalid
}
r, err := syscall.Write(file.fd, b)
return int(r), err
}
func (file *File) String() string {
return file.name
}
Es gibt kein implizites this. Um die Elemente der Struktur anzusprechen,
muss die Empfängervariable benutzt werden. Methoden werden nicht innerhalb der
struct-Deklaration deklariert. Die struct-Deklaration enthält
nur Datenelemente. Methoden können für fast alle Typen definiert, auch für Integer,
auch für Arrays und nicht nur für structs. Ein Array-Beispiel folgt später.
Die String-Methode nennen wir so wegen einer Druckkonvention, die wir später
beschreiben wollen.
Die Methoden benutzen die öffentliche Variable os.ErrInvalid, um den Unix-Fehlerkode
EINVAL (in der error-Version) zurückzugeben.
Die os-Bibliothek definiert einen Standard solcher Fehlerwerte.
Jetzt können wir unser neues Paket benutzen:
package main
import (
"./file"
"fmt"
"os"
)
func main() {
hello := []byte("Hallo, Welt\n")
file.Stdout.Write(hello)
f, err := file.Open("/gibts/nicht")
if f == nil {
fmt.Printf("Kann Datei nicht öffnen; Fehler=%s\n", err.Error())
os.Exit(1)
}
}
Mit dem Kode "./" beim Import von "./file" nimmt der Compiler
unser eigenes Paket anstatt eines aus dem Verzeichnis der installierten Pakete.
(Aber "file.go" muss umgewandelt worden sein, bevor wir es importieren
können.)
So können wir jetzt kompilieren und unser Programm starten. Unter Unix sieht das so aus:
$ 6g file.go # Paket file umwandeln
$ 6g helloworld3.go # Paket main umwandeln
$ 6l -o helloworld3 helloworld3.6 # Binden - "file" muss nicht genannt werden
$ ./helloworld3
Hallo, Welt
Kann Datei nicht öffnen; Fehler=No such file or directory
$
Ein verrückendes "cat"
Hier ist, aufbauend auf dem file-Paket, eine vereinfachte Version des
Unix-Dienstes cat(1), progs/cat.go:
package main
import (
"./file"
"flag"
"fmt"
"os"
)
func cat(f *file.File) {
const NBUF = 512
var buf [NBUF]byte
for {
switch nr, er := f.Read(buf[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: Fehler beim Lesen von %s: %s\n", f, er)
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
if nw, ew := file.Stdout.Write(buf[0:nr]); nw != nr {
fmt.Fprintf(os.Stderr, "cat: Fehler beim Schreiben von %s: %s\n", f, ew)
os.Exit(1)
}
}
}
}
func main() {
flag.Parse() // Absuchen der Argumentliste und setzen der Schalter
if flag.NArg() == 0 {
cat(file.Stdin)
}
for i := 0; i < flag.NArg(); i++ {
f, err := file.Open(flag.Arg(i))
if f == nil {
fmt.Fprintf(os.Stderr, "cat: Kann %s nicht öffnen: Fehler=%s\n", flag.Arg(i), err)
os.Exit(1)
}
cat(f)
f.Close()
}
}
Dem solten Sie inzwischen leicht folgen können, nur die switch-Anweisung
bringt nochmal etwas Neues. Genauso wie eine for-Schleife können if
und switch eine Initialisierungs-Anweisung enthalten. Das switch
in cat benutzt eine solche, um die Variablen nr und er
zu erzeugen, die die Rückgabewerte vom Aufruf von f.Read aufnehmen.
(Das if kurz darauf tut ähnliches.)
Die switch-Anweisung ist eine allgemeine, d.h. sie wertet die Cases aus,
von oben nach unten bis zum zum ersten zutreffenden, und die Case-Ausdrücke brauchen
weder Konstanten noch etwa Integer zu sein, wenn sie nur alle vom selben Typ sind.
Da der switch-Wert hier nur true ist, könnten wir ihn auch weglassen
— dasgleiche gilt für die for-Anweisung: ein fehlender Wert bedeutet
true. Solch ein switch ist eigentlich eine if-else-Kette.
Und, wo wir gerade dabei sind, soll auch erwähnt werden, dass jedes case
implizit mit break endet.
Das Argument für file.Stdout.Write wird erzeugt, indem das Array buf
aufgeschnitten wird [englisch: to slice, A.d.Ü.].
Slices sind die Go-typische Art, mit Ein-/Ausgabepuffern umzugehen.
Bauen wir nun eine Variante von cat, die optional den
rot13-Algorithmus auf die Eingabe anwendet. Das ginge auch ganz einfach byteweise,
aber stattdessen wollen wir die Go-Variante des Interface benutzen.
Die Routine cat benutzt nur zwei Methoden von f, nämlich
Read und String. Definieren wir also zunächst ein
Interface mit genau diesen beiden Methoden. Hier der Kode aus progs/cat_rot13.go:
type reader interface {
Read(b []byte) (ret int, err error)
String() string
}
Man sagt, dass jeder Typ mit den beiden Methoden von reader —
egal, welche Methoden es außerdem noch gibt — dieses Interface implementiert.
Weil file.File diese Methoden implementiert, implementiert es auch das
reader-Interface. Wir könnten jetzt an cat
herumfummeln, so dass reader anstatt *file.File akzeptiert würde,
aber machen wir's doch hübscher: Wir kreieren einen neuen Typ, der
reader implementiert, der einen existierenden reader kapselt
und außerdem rot13 auf die Daten anwendet. Dafür definieren wir den Typ und
implementieren die Methoden, und ohne weitere Kodepflege erhalten wir eine zweite
Implementierung von reader.
type rotate13 struct {
source reader
}
func newRotate13(source reader) *rotate13 {
return &rotate13{source}
}
func (r13 *rotate13) Read(b []byte) (ret int, err error) {
r, e := r13.source.Read(b)
for i := 0; i < r; i++ {
b[i] = rot13(b[i])
}
return r, e
}
func (r13 *rotate13) String() string {
return r13.source.String()
}
// Ende der rotate13-Implementierung
(Die in Read gerufene Funktion rot13 ist trivial und nicht wert, hier
wiedergegeben zu werden.)
Um die neue Eigenschaft auch nutzen zu können, definieren wir einen Schalter:
var rot13Flag = flag.Bool("rot13", false, "rot13(Eingabe)")
und nutzen ihn in der kaum geänderten cat-Funktion:
func cat(r reader) {
const NBUF = 512
var buf [NBUF]byte
if *rot13Flag {
r = newRotate13(r)
}
for {
switch nr, er := r.Read(buf[:]); {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: Fehler beim Lesen von %s: %s\n", r, er)
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
nw, ew := file.Stdout.Write(buf[0:nr])
if nw != nr {
fmt.Fprintf(os.Stderr, "cat: Fehler beim Schreiben von %s: %s\n", r, ew)
os.Exit(1)
}
}
}
}
(Wir hätten das Kapseln auch in main erledigen und damit cat
fast unberührt lassen können, mit Ausnahme des Parametertyps. Betrachten Sie das als
Übungsaufgabe.)
Im if am Anfang von cat wird getan, was zu tun ist:
Wenn der rot13-Schalter gesetzt ist,
pack' den mitgegebenen reader in ein rotate13 und mach weiter
wie gewohnt. Beachten Sie, dass die Variablen des Interface Werte sind und keine Zeiger:
der Parameter ist vom Typ reader und nicht *reader, auch wenn
es unter der Haube einen Zeiger auf ein struct beherbergt.
Hier sieht man cat in Aktion:
$ echo abcdefghijklmnopqrstuvwxyz | ./cat
abcdefghijklmnopqrstuvwxyz
$ echo abcdefghijklmnopqrstuvwxyz | ./cat --rot13
nopqrstuvwxyzabcdefghijklm
$
Anhänger der Dependency-Injection dürfen jubeln: so einfach ist es, die Implementierung einer Dateinummer zu ersetzen!
Interfaces sind ein charakteristisches Merkmal von Go. Ein Interface wird dann von einem
Typ implementiert, wenn der Typ alle im Interface deklarierten Methoden implementiert.
Das heißt auch, dass ein Typ beliebig viele verschiedene Intefaces implementieren kann.
Es gibt keine Typ-Hierarchie, alles kann mehr ad hoc geschehen — wie wir bei
rot13 sehen konnten. Der Typ file.File implementiert
reader; er könnte genausogut writer implementieren, oder irgendein
anderes Interface, das Methoden des Typs zusammenfasst — wie es die Situation gerade
erfordert. Oder denken Sie nur an das leere Interface:
type Empty interface {}
Jeder Typ implementiert das leere Interface, und das macht es nützlich für Container und ähnliches.
Sortieren
Interfaces bieten eine einfache Form des Polymorphismus. Sie trennen sauber die Definition dessen, was ein Objekt tut, davon, wie es das tut, und erlauben, dass unterschiedliche Implementierungen zu verschiedenen Zeiten dasselbe Interface vertreten.
Betrachten Sie zum Beispiel diesen einfachen Sortieralgorithmus aus progs/sort.go:
func Sort(data Interface) {
for i := 1; i < data.Len(); i++ {
for j := i; j > 0 && data.Less(j, j-1); j-- {
data.Swap(j, j-1)
}
}
}
Der Kode braucht nur drei Methoden, die wir im Interface von Sort kapseln:
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
Wir dürfen Sort auf jeden Typ anwenden, der Len, Less,
und Swap implementiert. Das sort-Paket enthält die nötigen Methoden,
für Arrays von Integern, Strings usw. Hier ist der Kode für int-Arrays:
type IntSlice []int
func (p IntSlice) Len() int { return len(p) }
func (p IntSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p IntSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
Das sind Methoden für Typen, die kein struct sind. Sie könnten aber Methoden
für jeden beliebigen Typ definieren, der in Ihrem Paket definiert und benannt ist.
Und hier eine Testroutine aus progs/sortmain.go. Sie benutzt eine weitere
Funktion aus dem sort-Paket, die hier der Kürze wegen weggelassen wurde; eine
Funktion um zu testen, ob das Ergebnis sortiert vorliegt.
func ints() {
data := []int{74, 59, 238, -784, 9845, 959, 905, 0, 0, 42, 7586, -5467984, 7586}
a := sort.IntSlice(data)
sort.Sort(a)
if !sort.IsSorted(a) {
panic("fail")
}
}
Wenn wir einen neuen Typ sortieren können wollen, müssen wir nur die drei Methoden für diesen Typ implementieren. Etwa so:
type day struct {
num int
shortName string
longName string
}
type dayArray struct {
data []*day
}
func (p *dayArray) Len() int { return len(p.data) }
func (p *dayArray) Less(i, j int) bool { return p.data[i].num < p.data[j].num }
func (p *dayArray) Swap(i, j int) { p.data[i], p.data[j] = p.data[j], p.data[i] }
Die Beispiele für formatiertes Drucken bisher waren eher anspruchslos. In diesem Abschnitt zeigen wir, wie formatiertes Ein-/Ausgeben in Go gut gemacht wird.
Einfache Anwendungen des fmt-Pakets, welches Printf,
Fprintf usw. implementiert, haben wir schon gesehen.
Im fmt-Paket wird Printf mit dieser Signatur deklariert:
Printf(format string, v ...) (n int, errno error)
Das ... steht für die variabel lange Argumentliste, die in C mit dem
stdarg.h-Makro gehandhabt würde, die aber in Go mittels eines leeren Interfaces
(interface {}) weitergereicht wird, um dann mit der Reflektions-Bibliothek
ausgepackt zu werden. Es gehört hier nicht zum Thema, aber der Gebrauch von Reflektion hilft,
einige nette Eigenschaften des Go-Printf zu erklären, was damit zusammenhängt,
dass Printf den Typ seiner Parameter dynamisch bestimmen kann.
Zum Beispiel muss in C jedes Format zum Typ des Parameters passen. Das ist in Go einfacher.
Statt %llud sagen Sie einfach %d. Das Printf kennt die
Größe und Vorzeicheneigenschaft des Integers und kann das Richtige für Sie tun. Das Kodestück:
var u64 uint64 = 1<<64-1
fmt.Printf("%d %d\n", u64, int64(u64))
druckt:
18446744073709551615 -1
Und mehr: Wenn Sie faul sein möchten, druckt das Format %v
jeden Wert, sogar ein Array oder eine Struktur, in einem einfachem, angemessenem Stil.
Die Ausgabe von:
type T struct {
a int
b string
}
t := T{77, "Sunset Strip"}
a := []int{1, 2, 3, 4}
fmt.Printf("%v %v %v\n", u64, t, a)
ist:
18446744073709551615 {77 Sunset Strip} [1 2 3 4]
Das Formatieren können Sie sich komplett sparen, wenn Sie Print oder
Println anstatt Printf benutzen. Diese Routinen formatieren
vollautomatisch. Print druckt einfach die Elemente mit einer Entsprechung von
%v, während Println noch Leerzeichen zwischen den Parametern und
einen Zeilenvorschub am Ende einfügt. Die Ausgabe beider folgenden Zeilen ist identisch mit
der obigen vom Printf:
fmt.Print(u64, " ", t, " ", a, "\n")
fmt.Println(u64, t, a)
Wenn Printf oder Print einen Ihrer eigenen Typen formatieren soll,
spendieren Sie diesem Typ die Methode String, die einen String zurückgibt.
Die Print-Routinen werden den Wert daraufhin untersuchen, ob er die Methode implementiert,
und wenn ja, sie statt anderer Formatierungen auch benutzen. Hier ist ein einfaches Beispiel:
type testType struct {
a int
b string
}
func (t *testType) String() string {
return fmt.Sprint(t.a) + " " + t.b
}
func main() {
t := &testType{77, "Sunset Strip"}
fmt.Println(t)
}
Weil *testType die String-Methode besitzt, wird die
Standard-Formatierung sie benutzen und folgendes ausgeben:
77 Sunset Strip
Beachten Sie, dass die String-Methode fürs Formatieren Sprint
(die naheliegend Go-Variante; sie gibt einen String zurück) ruft; spezielle Formatierer
können die fmt-Bibliothek rekursiv benutzen.
Eine weitere Fähigkeit von Printf ist, dass es mit %T eine
String-Darstellung des Typs zum Wert druckt; das kann nützlich sein bei der Fehlersuche in
polymorphem Kode.
Komplett individualisierte Druckformate zu schreiben, ist möglich, mit Schaltern und Nachkommastellen und dem ganzen Drumherum, aber das führt uns zu weit vom Thema weg und soll Ihnen als Erkundungsübung bleiben.
Sie dürfen natürlich trotzdem fragen, wie Printf herausfindet, ob ein Typ
die String-Methode implementiert. Nun, eigentlich fragt es, ob der Wert
in eine Interface-Variable passt, die diese Methode implementiert. Kurz skizziert
tut es mit einer Variablen v folgendes:
type Stringer interface {
String() string
}
s, ok := v.(Stringer) // Testen, ob v implementiert "String()"
if ok {
result = s.String()
} else {
result = defaultOutput(v)
}
Der Kode benutzt eine Typprüfung (v.(Stringer)), um zu prüfen, ob der Wert
in v dem Stringer-Interface genügt; wenn ja, wird
s zur Interface-Variablen mit der implementierten Methode und ok
wird auf true gesetzt. Dann benutzen wir die Interface-Variable zum Rufen der
Methode.
(Auch wenn wir es nur hier erwähnen, ist das "Komma, ok"-Muster die Go-typische Methode,
den Erfolg von Operationen zu testen, also von Operationen wie Typ-Konversion,
Map-Aktualisierung, Kommunikation, ...) Wenn der Wert dem Interface nicht genügt,
wird ok auf false gesetzt.
In obigem Kodestück folgt der Name Stringer einer Konvention, die besagt,
dass wir für Ein-Methoden-Interfaces wie dieses ein "[e]r" an den Methodenamen anhängen.
Mit Stringer verwandt ist das Interface,
das durch den integrierten error-Typ definiert ist, nämlich so:
type error interface {
Error() string
}
Abgesehen von den Methodennamen (Error gegenüber String)
sieht das wie ein Stringer aus; der andere Name garantiert, dass Typen,
die den Stringer implementieren nicht ungewollt auch das
error-Interface implementieren.
Aber, natürlich, erkennen Printf & Co das error-Interface
genauso wie den Stringer; den Fehler als String zu drucken ist also trivial.
Eine letzte Besonderheit: Um die Sammlung komplett zu machen, gibt es neben
Printf usw. und Sprintf usw. auch Fprintf usw.
Anders als in C ist der erste Parameter von Fprintf keine Datei sondern
eine Variable vom Typ io.Writer, einem Interface-Typ, definiert in der
io-Bibliothek:
type Writer interface {
Write(p []byte) (n int, err error)
}
(Das ist ein weiteres Interface nach der genannten Konvention, dieses Mal für
Write; es gibt auch io.Reader, io.ReadWriter
und so fort.)
Dadurch können Sie Fprintf auf jeden Typ anwenden, der eine
Write-Methode implementiert, also nicht nur auf Dateien sondern auch auf
Netzwerk-Kanäle, Puffer, auf was immer sie wollen.
Primzahlen
Wir kommen jetzt zu Prozessen und ihrer Kommunikation — kurz: zu Nebenläufigkeit. Das ist ein weites Feld und weil wir uns kurzfassen möchten, setzen wir das Thema als bekannt voraus.
Ein Klassiker in diesem Zusammenhang ist das Primzahlensieb. (Das Sieb des Eratosthenes ist ein effizienterer Algorithmus als der hier präsentierte, wir sind aber im Moment mehr an Nebenläufigkeit als an Algorithmen interessiert.) Es bekommt einen Eingabestrom, bestehend aus allen natürlichen Zahlen, und schickt sie durch eine Reihe von Filtern, für jede Primzahl einen, um alle Vielfachen der jeweiligen Primzahl auszusortieren. In jedem Bearbeitungsschritt existieren die Filter aus den bis dahin ermittelten Primzahlen. Die nächste Zahl, die durchfällt, ist die nächste Primzahl und löst den Bau des nächsten Filters aus.
Hier ein Flussdiagramm: jedes Rechteck steht für ein Filterelement, dessen Bau durch die Zahl ausgelöst wurde, die als erste durch alle Elemente davor geschlüpft war:
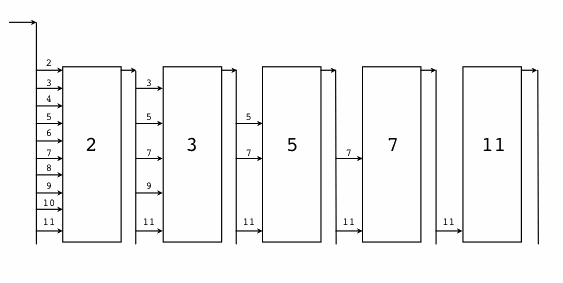
Den Integerstrom erzeugen wir mit einem Go-Channel, einem Kommunikationskanal,
der zwei nebenläufige Berechnungen verbindet (die Idee ist geborgt von den CSP-Abkömmlingen).
Channel-Variablen in Go sind Referenzen auf Laufzeitobjekte, die die Kommunikation koordinieren;
wie bei Maps oder Slices benutzt man make zum Erzeugen neuer Channels.
Die erste Funktion in progs/sieve.go ist:
// Schick' die Folge 2, 3, 4, ... in den Kanal 'ch'.
func generate(ch chan int) {
for i := 2; ; i++ {
ch <- i // Schick 'i' in den Kanal 'ch'.
}
}
Die generate-Funktion schickt 2, 3, 4, 5 usw. an seinen Parameter,
den Kanal ch, und zwar mit dem binären Kommunikationsoperator <-.
Channel-Operationen blockieren: wenn also kein Empfänger vorhanden ist, für den Wert
in ch, dann wartet die Operation, bis einer verfügbar wird.
Die filter-Funktion hat drei Parameter: einen Eingabekanal, einen Ausgabekanal
und eine Primzahl. Sie kopiert die Werte von der Eingabe zur Ausgabe, verwirft aber alles,
was durch die Primzahl teilbar ist. Der unäre Kommunikationsoperator <-
empfängt (ruft ab) den nächsten Wert aus dem Kanal.
// Kopiere die Werte vom Kanal 'in' zum Kanal 'out',
// lösche aber alle die, die durch 'prime' teilbar sind.
func filter(in, out chan int, prime int) {
for {
i := <-in // Empfange einen neuen Wert für die Variable 'i' aus dem Kanal 'in'.
if i % prime != 0 {
out <- i // Schick 'i' in den Kanal 'out'.
}
}
}
Generator und Filter arbeiten simultan. Go hat ein eigenes Modell für
Prozess/Thread/leichtgewichtiger Prozess/Koroutine; um also Verwechslung zu vermeiden,
nennen wir die nebenläufigen Berechnungen in Go Goroutinen. Um eine Goroutine
zu starten, ruft man die Funktion auf und setzt davor das Schlüsselwort go;
das startet die Funktion parallel zur laufenden Berechnung, aber im selben Adressraum:
go sum(hugeArray) // Berechne die Summe im Hintergrund
Wenn Sie wissen wollen, wann die Berechnung beendet ist, schicken Sie einen Kanal mit, auf dem zurückgemeldet werden kann:
ch := make(chan int)
go sum(hugeArray, ch)
// ... Tu eine Weile etwas anderes
result := <-ch // Warte aufs Ergebnis und ruf es ab
Zurück zu unserem Primzahlensieb. So wird die Pipeline zusammengebaut:
func main() {
ch := make(chan int) // Erzeuge einen ersten Kanal.
go generate(ch) // Starte generate() als Goroutine.
for i := 0; i < 100; i++ { // Druck' die ersten hundert Primzahlen.
prime := <-ch
fmt.Println(prime)
ch1 := make(chan int)
go filter(ch, ch1, prime)
ch = ch1
}
}
Die erste Zeile von main erzeugt einen ersten Kanal für generate,
welches gleich darauf gestartet wird.
Sobald eine neue Primzahl aus dem Kanal heraushüpft, wird ein neuer filter an
die Pipeline angehängt und dessen Ausgabe wird der neue Wert von ch.
Unser Siebprogramm kann man so zurechtbiegen, dass es ein für diese Art von Programmierung
typisches Muster benutzt. Hier die variierte Form von generate, zu finden in
progs/sieve1.go:
func generate() chan int {
ch := make(chan int)
go func() {
for i := 2; ; i++ {
ch <- i
}
}()
return ch
}
Diese Version macht alles intern. Es erzeugt den Ausgabekanal, setzt eine Goroutine in Gang, die ein Funktionsliteral laufen lässt und gibt den Kanal an den Rufenden zurück. Sie ist eine Fabrik für nebenläufiges Abarbeiten: Starten einer Goroutine und Rückgabe einer Verknüpfung zu ihr.
Die Schreibweise als Funktionsliteral (innerhalb der go-Anweisung)
erlaubt uns, eine anonyme Funktion
zu konstruieren und auf der Stelle aufzurufen. Beachten Sie, dass die lokale Variable
ch dem Funktionsliteral zur Verfügung steht und auch gültig bleibt, nachdem
generate geendet hat.
Diegleiche Änderung kann man an filter vornehmen:
func filter(in chan int, prime int) chan int {
out := make(chan int)
go func() {
for {
if i := <-in; i%prime != 0 {
out <- i
}
}
}()
return out
}
Die Hauptschleife der sieve-Funktion wird dadurch einfacher und klarer,
und, wo wir gerade dabei sind, machen wir doch daraus auch eine Fabrik:
func sieve() chan int {
out := make(chan int)
go func() {
ch := generate()
for {
prime := <-ch
out <- prime
ch = filter(ch, prime)
}
}()
return out
}
Die Schnittstelle zwischen main und Primzahlensieb ist nun ein Kanal für
Primzahlen:
func main() {
primes := sieve()
for i := 0; i < 100; i++ { // Druck' die ersten hundert Primzahlen.
fmt.Println(<-primes)
}
}
Bündeln und Verteilen
Mithilfe von Kanälen ist es möglich, mehrere unabhängige Klient-Goroutinen zu bedienen ohne
explizit einen Multiplexer zu schreiben. Der Trick ist, dem Server einen Kanal als Nachricht
zu schicken, über den er dem Sender antworten kann.
Ein echtes Klient-Server-Programm würde eine Menge Kode bedeuten; deshalb hier nur ein
simpler Ersatz, der das Konzept illustriert. Wir beginnen mit der Definition eines
request-Typs, mit eingebettetem Kanal, der beim Antworten benutzt wird.
type request struct {
a, b int
replyc chan int
}
Der Server wird einfach gestrickt: er soll einfache binäre Operationen auf Integer ausführen. Hier der Kode, der die Operation aufruft und die Anfrage beantwortet:
type binOp func(a, b int) int
func run(op binOp, req *request) {
reply := op(req.a, req.b)
req.replyc <- reply
}
Die Typdeklaration macht binOp zu einer Funktion mit zwei Ganzzahlen als Parameter
und einer dritten als Rückgabewert.
Die server-Routine kreiselt ohne Ende, wobei sie Anfragen empfängt und,
um durch langlaufende Operationen nicht blockiert zu werden, für die eigentliche Arbeit
Go-Routinen startet:
func server(op binOp, service <-chan *request) {
for {
req := <-service
go run(op, req) // nicht warten
}
}
Die Signatur von server enthält etwas Neues: Der Typdeklaration des Kanals
service legt die Richtung der Kommunikation fest. Ein Kanal mit dem
nackten chan-Typ kann zum Senden und zum Empfangen benutzt werden.
Verziert man den Typ mit einem Pfeil, so legt man damit fest, dass der Kanal
nur zum Senden (chan<-) oder nur zum Empfangen (<-chan)
dienen soll. Der Pfeil zeigt zum chan hin oder von ihm weg,
genauso wie die Daten in den Kanal strömen oder aus ihm heraus.
In der server-Funktion ist service <-chan *request also ein
reiner Empfangskanal, so dass die Funktion darüber nur Anfragen lesen kann.
Wir erzeugen eine Instanz von server wie gewohnt, indem wir ihn starten
und den angeschlossenen Kanal zurückliefern:
func startServer(op binOp) chan<- *request {
req := make(chan *request)
go server(op, req)
return req
}
Der zurückgegeben Kanal ist ein reiner Sendekanal (chan<- *request),
obwohl er als bidirektionaler erzeugt wird.
Das Empfangsende wird dem server übergeben, während das Sendeende an den
Aufrufer von startServer zurückgeht.
Bidirektionale Kanäle können unidirektionalen zugewiesen werden — umgekehrt geht das
nicht. Deklarieren Sie Kanäle richtungsbehaftet, z.B. in der Signatur von Funktionen,
so dass Ihnen das Go-Typsystem helfen kann, Kanäle korrekt zu benutzen.
Übrigens, es ist sinnlos, unidirektionale Kanäle mit make anzulegen —
man könnte mit ihnen nicht kommunizieren. Die Variable, der ein Kanal zugewiesen wird,
ist es, die über seine Rolle als Ein- oder Ausgabehälfte entscheidet.
Hier ein einfacher Test. Er startet den Server mit einer Additions-Operation und
schickt N Anfragen los ohne auf die Antworten zu warten. Erst danach werden
die Ergebnisse abgefragt und geprüft.
func main() {
adder := startServer(func(a, b int) int { return a + b })
const N = 100
var reqs [N]request
for i := 0; i < N; i++ {
req := &reqs[i]
req.a = i
req.b = i + N
req.replyc = make(chan int)
adder <- req
}
for i := N-1; i >= 0; i-- { // egal in welcher Reihenfolge
if <-reqs[i].replyc != N + 2*i {
fmt.Println("Fehler bei", i)
}
}
fmt.Println("Fertig!")
}
Eine Schwachstelle dieses Programms ist, dass der Server nicht sauber beendet wird. Wenn
main endet, wartet noch eine ganze Reihe von Go-Routinen auf Nachrichten.
Um das abzustellen, bauen wir den Server mit einem zweiten, dem quit-Kanal:
func startServer(op binOp) (service chan<- *request, quit chan< bool) {
service = make(chan *request)
quit = make(chan bool)
go server(op, service, quit)
return service, quit
}
Der quit-Kanal wird der server-Funktion übergeben, die ihn
folgendermaßen benutzt:
func server(op binOp, service <-chan *request, quit <-chan bool) {
for {
select {
case req := <-service:
go run(op, req) // nicht warten
case <-quit:
return
}
}
}
Im Kode von server entscheidet die select-Anweisung, welches
case weitermachen darf, welcher Kanal bearbeitet werden kann. Wenn alle
blockieren, wartet sie, bis eines davon weitermachen kann; wenn mehrere können, wählt es
eines aus. In unserem Fall erlaubt das select dem Server, alle Anfragen
zu akzeptieren, bis er eine quit-Nachricht erhält. Daraufhin springt er an
sein Ende und damit heraus aus der Verarbeitungsschleife.
Alles, was noch zu tun bleibt, ist, am Ende von main den
quit-Kanal "anzublinken":
adder, quit := startServer(func(a, b int) int { return a + b })
...
quit <- true
Es gäbe noch so viel mehr zu erzählen über Nebenläufigkeit und Go. Hier wollten wir Ihnen nur ein paar Grundlagen nahebringen.