Die Nutzung dieses Werks ist unter den Bedingungen der "Creative Commons Namensnennung - Keine Bearbeitungen 4.0 International"-Lizenz erlaubt.
Starke Typen
Dieser Aufsatz macht auf einen hilfreichen Aspekt von Datentypen aufmerksam.
Vor kurzem habe ich gleich mehrere Tage gebraucht, um nur einen Datenpflegedialog zu entwanzen. Immer wieder kamen falsche Daten an der Oberfläche an ... Oder eine Fehlermeldung, dass irgendwas nicht gefunden worden sei ... Obwohl es doch da war! ... Programmiereralltag.
Zugegeben, der genannte Dialog ist nicht ganz trivial. Auf der Bedienoberfläche gibt es Felder für Texteingaben, verschiedene Check- und Comboboxen und mehrere Listen. Die Oberfläche (C++/Qt) kommuniziert über JSON mit einem Logikserver (Go), dieser wiederum wiederum über JSON mit einem Datenserver (Go), der über SQL eine Datenbank (Sqlite) bedient.
Kompliziert? Ja, vielleicht. Aber die Oberfläche funktionierte schon, und die Kommunikation zwischen den vier Ebenen auch. Nein, die Fehler steckten alle in der Logik.
Und dann stellte sich heraus, dass die meisten dieser Fehler sich sehr ähnlich waren. Ursache war dann immer eine Kombination aus Variablen mit verwechselbaren Typen und Tippfehlern, wie sie typischerweise entstehen durch Copy und Paste und Find 'n' Replace, und dann doch noch was vergessen. (Über diese Sorte von Fehlern schreibt Andrey Karpov in "The Last Line Effect".)
Sehen wir uns mal einen Ausschnitt aus dem Datenmodell an:
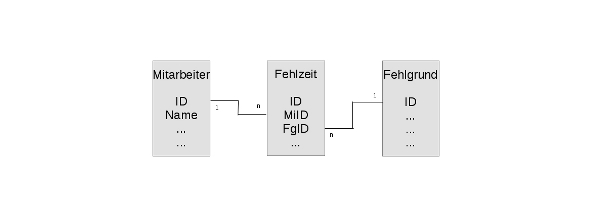
Fehlzeit ist jeweils ein Zeitraum (von, bis) und mit Fehlgrund ist sowas wie "Urlaub" oder "Krankheit" gemeint.
Im Programm hat man es dann mit Variablen wie
Mitarbeiter.ID, Fehlzeit.ID, Fehlzeit.MiID,
Fehlzeit.FgID und Fehlgrund.ID zu tun.
Es sind dies Zugriffsschlüssel auf Datenbanktabellen ... Und alle sind vom
Typ int32 ... Und niemand hindert uns daran, z.B. eine
Mitarbeiter-ID versehentlich als Fehlgrund-ID zu benutzen ...
und damit eine mittlere Katastrophe auszulösen:
Fehlzeit.FgID = Mitarbeiter.ID
Doch halt! Es gibt jemanden, der uns hindern könnte. Der Compiler nämlich.
In einer Sprache mit strenger Typprüfung, wie es Go eine ist, weist man sachlich verschiedenen Variablen entsprechend verschiedene Typen zu. Also in unserem Beispiel deklarieren wir zuerst die Typen:
type (
MIID int32 // identifiziert einen Mitarbeiter
FZID int32 // identifiziert eine Fehlzeit
FGID int32 // identifiziert einen Fehlgrund
)
Und dann die Variablen:
var Mitarbeiter struct (
ID MIID
// ...
)
var Fehlgrund struct (
ID FGID
// ...
)
var Fehlzeit struct (
ID FZID
MiID MIID
FgID FGID
// ...
)
Und das war's schon. Der Compiler meldet jetzt:
...: cannot use Mitarbeiter.ID (type MIID) as type FGID in assignment
Der Compiler haut uns also auf die Finger, wenn wir nach einem Fehlgrund mit einer Mitarbeiter-ID suchen wollen ... oder wenn wir Äpfel mit Birnen vergleichen wollen ... und eine ganze Fehlerklasse verschwindet.
Bei Schlüsselfeldern wie den genanntes IDs sind eigene Typen besonders
ertragreich. Aber man kann genausogut auch ganz belanglose Variablen absichern.
Ein Mitarbeitername ist etwas komplett anderes als ein Projektname; also
bekommt jener den Typ MINAME und dieser PJNAME,
und alles wird gut.
Juni 2014
