Diagnostics — Deutsche Übersetzung
- Das Original:
-
https://golang.org/doc/diagnostics.html
Version of November 20, 2020 (go1.16) - Diese Übersetzung:
-
https://bitloeffel.de/DOC/golang/diagnostics_20210225_de.html
Stand: 25.02.2021
© 2020-21 Hans-Werner Heinzen @ Bitloeffel.de
Die Nutzung dieses Werks ist unter den Bedingungen der "Creative Commons Attribution 3.0"-Lizenz erlaubt.
Für Fachbegriffe und ähnliches gibt es hier noch eine Wörterliste.
Diagnostik
Einführung
Das Go-Ökosystem bietet eine breite Palette von Schnittstellen und Werkzeugen zum Erkennen von Logik- und Durchsatzproblemen in Go-Programmen. Dieser Artikel zählt die verfügbaren Werkzeuge auf und hilft Go-Anwendern bei der Wahl des richtigen für Ihre jeweiliges Problem.
Diagnosewerkzeuge kann man in folgende Kategorien einteilen:
- Profilmessung (profiling): Werkzeuge zur Profilmessung analysieren Komplexität und Kosten eines Go-Programms wie etwa Speichernutzung oder oft gerufene Funktionen, um "teure" Abschnitte eines Programms ausfindig zu machen.
- Ablaufverfolgung (tracing): Ablaufverfolgung ist eine Art der Instrumentierung von Kode zur Analyse von Verzögerungen (Latenzzeiten) während der Laufzeit eines Funktionsaufrufs oder einer Benutzeranfrage. Ablaufprotokolle bieten einen Überblick darüber, wie groß der Anteil der einzelnen Komponenten an der Gesamtlaufzeit eines Systems ist. Diese Protokolle können sich über mehrere Go-Prozesse erstrecken.
- Entwanzen (debugging): Entwanzen erlaubt es, Go-Programme zu unterbrechen und ihre Arbeit zu analysieren. Programmzustand und -fortschritt können so überprüft werden.
- Laufzeitzustände und Laufzeitereignisse: Das Kumulieren und Analysieren von Laufzeitzuständen und -ereignissen bietet eine abstrakten Sicht auf die Güte von Go-Programmen. Das Hochschnellen und Abfallen von Leistungsmerkmalen lassen Änderungen von Durchsatz, Nutzung und Leistung erkennen.
Hinweis: Einzelne Diagnosewerkzeuge können sich gegenseitig stören. Zum Beispiel verzerrt die genaue Analyse der Speichernutzung die Analyse der Prozessornutzung; und die Analyse des Blockierverhalten von Goroutinen beeinflusst das Nachverfolgen des Ablaufmanagers (scheduler). Benutzen Sie die Werkzeuge getrennt voneinander, dann bekommen Sie genauere Ergebnisse.
Profilmessung
Profilmessung (profiling) ist nützlich zum Auffinden teurer oder oft
gerufener Kodeabschnitte. Die Go-Laufzeitumgebung liefert
Profildaten
in einem Format, wie es vom Visualisierungswerkzeug
pprof
erwartet wird. Profildaten können beim Testen mit go test
oder mithilfe von Start- und Zielmarken aus dem Paket
net/http/pprof
gesammelt werden. Profildaten müssen zuerst gesammelt werden, und anschließend
müssen mit dem Werkzeug pprof die häufigsten Kodepfade gefiltert und angezeigt
werden.
Das Paket runtime/pprof bietet dafür vordefinierte Profile:
- cpu: Das CPU-Profil erkennt, an welcher Stelle ein Programm Zeit verbraucht, während es tatsächlich Prozessorzyklen konsumiert (also nicht, wenn es schläft oder auf Ein- oder Ausgabeoperationen wartet).
- heap: Das Haldenprofil meldet stichprobenweise Speicherzuteilungen; damit überwacht man die aktuelle und vergangene Speichernutzung und sucht nach Speicherlecks.
- threadcreate: Das Thread-Erzeugungs-Profil meldet die Programmabschnitte, welche neue Betriebssystem-Threads erzeugen.
- goroutine: Das Goroutinen-Profil zeigt für alle Goroutinen den aktuellen "Stacktrace".
-
block: Das Blockierprofil zeigt, wo Goroutinen auf
Synchronisations-Elementarfunktionen (inklusive Zeitgeberkanäle) warten.
Das Blockierprofil ist standardmäßig nicht aktiv; aktivieren Sie es über
runtime.SetBlockProfileRate. -
mutex: Das Mutex-Profil meldet Zugriffskonflikte. Wenn Sie
vermuten, dass Ihr Prozessor wegen Zugriffskonflikten nicht ausgelastet wird,
benutzen Sie dieses Profil. Das Mutex-Profil ist standardmäßig nicht aktiv;
aktivieren Sie es über
runtime.SetMutexProfileFraction.
Welche Profilmessungen für Go-Programme gibt es außerdem noch?
Unter Linux kann man die perf-Tools zur Profilmessung von Go-Programmen benutzen. Perf kann Profile messen und cgo/SWIG-Kode von Kernelkode unterscheiden, kann also Einblicke in Performanzengpässe zwischen Programm- und Kernelkode gewähren. Unter macOS kann die Instrumentierungssammlung Instruments benutzt werden.
Kann ich Profilmessung im Produktionsbetrieb einsetzen?
Ja, das ist gefahrlos möglich — allerdings bringen einige der Profile (z.B. das CPU-Profil) Kosten mit sich. Sie sollten sich auf Performanzverluste einstellen. Die Performanzeinbuße kann abgeschätzt werden, indem man den zusätzlichen Aufwand für den Profiler misst, bevor man ihn in Produktion einsetzt.
Vielleicht wollen Sie bei Ihren produktiven Diensten regelmäßig das Profil vermessen. Ist es ein System mit vielen Kopien eines einzigen Prozesses, dann sind Sie auf der sicheren Seite, wenn Sie periodisch zufällig eine Kopie auswählen. Wählen Sie also einen produktiven Prozess, messen Sie dann alle Y Sekunden jeweils X Sekunden lang, sichern Sie die Ergebnisse für späteres Visualisieren und Analysieren; und das wiederholen Sie dann regelmäßig. Die Ergebnisse können manuell oder auch automatisiert auf ein Problem hin untersucht werden. Das Sammeln verschiedener Arten von Profildaten kann sich gegenseitig stören, weshalb empfohlen wird, Daten getrennt und nacheinander zu sammeln.
Wie visualisiert man Profildaten am besten?
Unsere Go-Werkzeuge können Profildaten als Text, Graph oder
callgrind-Visualisierung
darstellen, und zwar mithilfe von
go tool pprof.
Lesen Sie dazu
"Profiling Go programs".

Liste der teuersten Funktionsaufrufe in Textform.
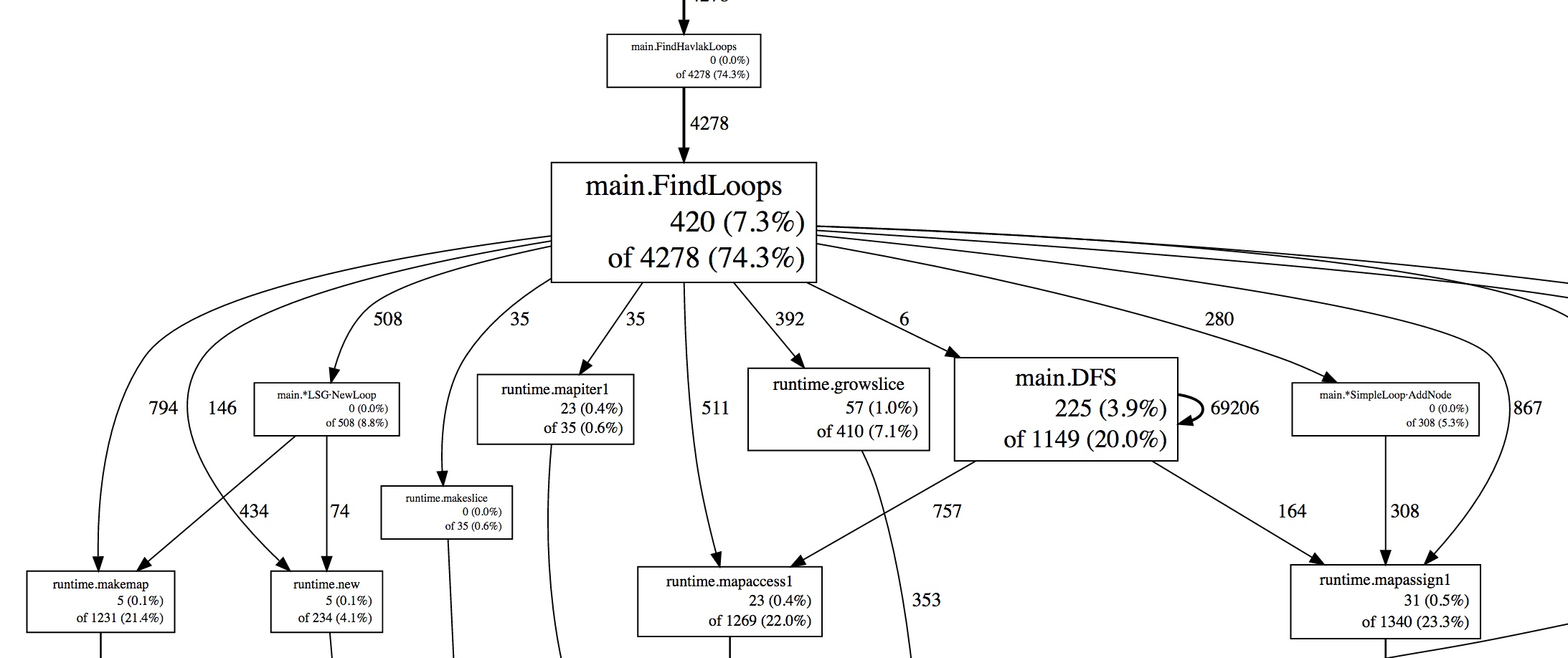
Darstellung der teuersten Funktionsaufrufe als Graph.
Die HTML-Darstellung zeigt die teuren Quellkodeabschnitte Zeile für Zeile auf einer
HTML-Seite. Im folgenden Beispiel wurden 530ms in der Funktion
runtime.concatstrings verbracht; die Kosten jeder Zeile werden angezeigt.

Darstellung der teuersten Funktionsaufrufe als HTML-Seite.
Eine andere Art, Profildaten anzuzeigen ist die in Form von Flammendiagrammen. Man kann sich dort auf einer bestimmten Abstammungslinie bewegen und die Ansicht von Kodeabschnitten vergößern und verkleinern. Das Original-pprof unterstützt Flammendiagramme.

Mit Flammendiagrammen lassen sich die teuersten Kodepfade aufspüren.
Ist mit den vordefinierten Profilen schon Schluss?
Nein, zusätzlich zu dem, was die Laufzeitumgebung bereitstellt, können benutzerdefinierte Profile mit pprof.Profile erzeugt werden; das Auswerten geschieht dann wieder mit den genannten Werkzeugen.
Kann ich die Profildatenbearbeiter (/debug/pprof/...) auf einen anderen Pfad und einen anderen Port ansetzen?
Ja. Das Paket net/http/pprof meldet seine Bearbeiter (handler)
beim Standard-Multiplexer (mux) an, doch Sie können sie auch selbst anmelden
mithilfe der vom Paket exportierten "Handler"-Funktionen.
Zum Beispiel wird im folgendem Kode der Bearbeiter pprof.Profile
für /custom_debug_path/profile den Port :7777 bedienen:
package main
import (
"log"
"net/http"
"net/http/pprof"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/custom_debug_path/profile", pprof.Profile)
log.Fatal(http.ListenAndServe(":7777", mux))
}
Ablaufverfolgung
Ablaufverfolgung (tracing) ist eine Art der Instrumentierung von Kode für die Analyse von Latenzzeiten über eine Kette von Funktionsaufrufen hinweg. Go bietet das Paket golang.org/x/net/trace als minimales Werkzeug für die Hintergrundverarbeitung (backend) je Go-Knoten, und stellt eine minimale Bibliothek zum Instrumentieren des Kodes zu Verfügung sowie eine einfache Steuerung. Go hat außerdem noch einen Ablaufverfolger, der Laufzeitereignisse in einem Zeitintervall aufspürt.
Ablaufverfolgung ermöglicht uns,
- zu instrumentieren und Latenzzeiten in einem Go-Prozess zu messen,
- Kosten bestimmter Aufrufe in einer langen Aufrufkette zu bestimmen, und
- Nutzungshäufigkeiten zu erkennen und herauszufinden, wie die Performanz verbessert werden kann. Ohne Ablaufdaten sind Flaschenhälse schwer zu erkennen.
In einem monolitischen System ist es relativ einfach, Diagnosedaten von den Programmbausteinen zu erhalten. Alle Teile arbeiten innerhalb eines Prozesses und melden ihre Protokolldaten, Fehler und andere Diagnosedaten an eine gemeinsame Ressource. Ist aber Ihr System erst einmal über den einen Prozess hinausgewachsen, wird also zu einem verteilten System, dann wird es auch schwerer, einen Aufruf vom Web-Server im Vordergrund zu allen Hintergrundprozessen zu verfolgen, bis endlich die Antwort an den Nutzer zurückgeht. Hier kommt die Verteilte Ablaufverfolgung zum Einsatz.
Verteilte Ablaufverfolgung ist eine Art der Instrumentierung von Kode für die Analyse von Latenzzeiten über die gesamte Laufzeit einer Benutzeranfrage. Wenn das System ein verteiltes ist und die gewöhnlichen Werkzeuge fürs Profilmessen und Entwanzen nicht mehr Schritt halten, werden Sie wohl für die Durchsatzanalyse Ihrer Benutzeranfragen und RPCs (remote procedure call) verteilte Werkzeuge benötigen.
Verteilte Ablaufverfolgung ermöglicht uns,
- zu instrumentieren und Latenzzeiten in großen Systemen zu messen,
- die Spur aller RPCs über die Laufzeit einer Benutzeranfrage hinweg zu verfolgen, und Integrationsprobleme zu erkennen, die nur in einer Produktionsumgebung sichtbar sind.
- herauszufinden, wie Performanz in unserem System verbessert werden kann. Viele Flaschenhälse sind nicht erkennbar, bevor nicht eine Sammlung von Ablaufdaten zur Verfügung steht, und
Das Go-Ökosystem bietet verschiedene verteilte Ablaufverfolgungs-Bibliotheken je Tracing-System als auch solche, die von der Art des Hintergrundsystems unabhängig sind.
Ist es möglich, irgendwie automatisch alle Funktionsaufrufe abzufangen und Protokolldaten zu erzeugen?
Das ist in Go nicht vorgesehen; Sie müssen Ihren Kode manuell instrumentieren, um Bereiche mit Anfangs- und Endemarken sowie mit Anmerkungen zu versehen.
Wie soll ich Ablauf-Kopfdaten in Go-Bibliotheken weitergeben?
Bezeichner (trace identifiers) und Markierungen (trace tags) fürs
Ablaufprotokoll können Sie mithilfe von
context.Context
weitergeben.
Bisher gibt es in der Industrie weder einen Standard für einen Ablaufschlüssel
(trace key) noch eine allgemein übliche Darstellung für Ablauf-Kopfdaten
(trace headers). Jeder, der Werkzeuge für die Ablaufverfolgung bereitstellt,
ist auch für die Weitergabe innerhalb seiner Go-Bibliothek verantwortlich
Welche Low-Level-Ereignisse aus der Standardbibliothek oder der Laufzeitumgebung kann man noch protokollieren?
In der Standardbibliothek und der Laufzeitumgebung wurden einige
Schnittstellen für das Melden von Low-Level-Ereignissen erweitert.
Zum Beispiel stellt
httptrace.ClientTrace
eine Schnittstelle zum Verfolgen von Low-Level-Ereignissen während der
Laufzeit einer abgehenden Anfrage zur Verfügung. Man bemüht sich
fortwährend, weitere Low-Level-Ereignisse der Laufzeitumgebung für die
Ablaufverfolgung bereitzustellen sowie Go-Anwendern zu erlauben, ihre
eigenen Ereignisse zu definieren und aufzuzeichnen.
Entwanzen
Entwanzen (debugging) heißt der Prozess, bei dem die Ursache für ein schlechten Programmverhalten festgestellt wird. Debugger helfen uns, den Programmablauf und dessen aktuellen Zustand zu verstehen. Es gibt mehrere Arten des Entwanzens; hier konzentrieren wir uns auf das Verknüpfen eines Debuggers mit einem Programm sowie das Arbeiten mit einem Speicherauszug (core dump).
Für Go werden vor allem folgende Debugger verwendet:
- Delve: Delve ist ein Debugger für die Programmiersprache Go. Es unterstützt die Go-Laufzeitarchitektur und Go's Standardtypen. Delve bemüht sich, ein für Go-Programme vollständiger und verläßlicher Debugger zu sein.
-
GDB:
Go unterstützt GDB sowohl mit dem Standard-Go-Compiler
gcals auch mit Gccgo. Allerdings unterscheiden sich verschiedene Aspekte der Stack-Verwaltung, der Thread-Nutzung und der Laufzeitumgebung von denen, die GDB erwartet. Das kann den Debugger irritieren, sogar dann, wenn das Programm mit gccgo umgewandelt wurde. GDB kann für Go-Programme genutzt werden, ist aber nicht ideal und kann Verwirrung stiften.
Wie gut kommen Debugger mit Go-Programmen zurecht?
Der Compiler gc führt Optimierungen durch, etwa
Funktionseinbettung (inlining) und Variablenpufferung (registerization).
Das erschwert das Entwanzen mit dem Debugger. Man bemüht sich fortwährend,
die Qualität von DWARF-Informationen zu verbessern, die für optimierte
Binärdateien genutzt werden. Bis dahin empfehlen wir, den zum Entwanzen
bestimmten Kode ohne Optimierungen umzuwandeln. Folgendes Kommando fertigt
ein Paket ohne Optimierungen durch den Compiler:
$ go build -gcflags=all="-N -l"
Als Teil der genannten Verbesserungen führte Go 1.10 einen neuen Schalter
für den Compiler ein: -dwarflocationlists. Dieser Schalter
veranlasst den Compiler, optimierten Binärdateien eine Liste von
Speicherorten hinzuzufügen. Folgendes Kommando fertigt ein Paket mit
Optimierungen und mit einer DWARF-Liste von Speicherorten:
$ go build -gcflags="-dwarflocationlists=true"
Welche Benutzerschnittstelle wird für Debugger empfohlen?
Zwar bieten sowohl Delve als auch GDB Zeilenkommandos (CLI) an, aber die meisten Integrierten Umgebungen (IDEs) haben eigene Schnittstellen fürs Entwanzen.
Ist es möglich Go-Programme nach dem Absturz (postmortem) zu untersuchen?
Eine Speicherauszugsdatei (core dump file) ist eine Datei, die den Speicherauszug sowie den Status eines laufenden Prozesses enthält. Sie wird zum Einen gebraucht, um ein Programm nach dem Absturz zu untersuchen, und zum Anderen, um seinen Zustand während der Ausführung zu verstehen. Für beide Anwendungen ist der Speicherauszug eine nützliche Hilfe. Es ist möglich, sich Speicherauszüge von Go-Programmen zu greifen und diese dann mit Delve oder GDB zu untersuchen; core dump debugging bietet eine Schritt-für-Schritt-Anleitung.
Laufzeitzustände und Laufzeitereignisse
Die Laufzeitumgebung liefert uns Statistikdaten und meldet interne Ereignisse, sodass Go-Anwender Performanz- und Nutzungsprobleme auf dieser Ebene beurteilen können.
man kann mit diesen Statistikdaten die allgemeine Güte und Performanz eines Go-Programms besser verstehen. Es folgen einige oft benutzte Statistik- und Zustandsdaten:
-
runtime.ReadMemStatsmeldet Kennzahlen, die mit Speicherzuweisung und mit Speicherbereinigung zu tun haben. Diese Daten zeigen an, wieviel Hauptspeicher ein Prozess belegt, ob der Prozess mit dem Speicher sinnvoll umgeht und wo Speicherlecks zu finden sind. -
debug.ReadGCStatsliest Statistikdaten über die automatische Speicherbereinigung (garbage collection). Es hilft zu erkennen, wieviel Resourcen auf Speicherbereinigungs-Pausen verwendet werden. Es protokolliert auch einen Zeitstrahl (timeline) mit diesen Pausen inklusive der Prozentanteile. -
debug.Stackgibt der aktuellen Stacktrace zurück. Dieser ist nützlich, um zu sehen, wieviele Goroutinen gerade aktiv sind, was sie tun und ob sie vielleicht blockiert sind. -
debug.WriteHeapDumpunterbricht die Ausführung aller Goroutinen und ermöglicht es Ihnen, einen Speicherauszug in eine Datei zu schreiben. Ein Speicherauszug (heap dump) ist eine Momentaufnahme des durch einen Go-Prozess genutzten Speichers zu einem bestimmten Zeitpunkt. Er enthält alle allozierten Objekte wie auch die Goroutinen, Finalisierungsmethoden und so weiter. -
runtime.NumGoroutinegibt die Anzahl der aktuell aktiven Goroutinen zurück. Dieser Wert kann beobachtet werden, um zu sehen, ob genügend Goroutinen benutzt werden oder um Goroutinen-Lecks zu finden.
Ablaufverfolger
Go bringt einen Ablaufverfolger mit, der eine breite Palette von
Laufzeitereignissen einfängt. Zeitplanung (scheduling), Systemaufrufe,
Speicherbereinigung und andere Ereignisse werden durch das Laufzeitsystem
gesammelt und steht zur Visualisierung mit dem Go-Werkzeug trace
zur Verfügung. Dieser Ablaufverfolger dient der Aufdeckung von Latenz-
und Nutzungsproblemen. Sie können untersuchen, wie gut die CPU genutzt wird,
und wann Netzwerk- oder Systemaufrufe Grund für Bevorzugung (preemption)
von Goroutinen ist.
Der Ablaufverfolger hilft,
- zu verstehen, wie Ihre Goroutinen ausgeführt werden,
- einige zentrale Laufzeitereignisse wie etwa die Arbeitsgänge der Speicherbereinigung zu verstehen, und
- schlecht paralellisierte Verarbeitung zu erkennen.
Allerdings ist dieses Werkzeug nicht besonders gut, um kritische Kodeabschnitte zu finden, etwa solche, die Speicher oder Prozessor übermäßig belasten. Nutzen Sie dafür stattdessen Werkzeuge der Profilmessung.
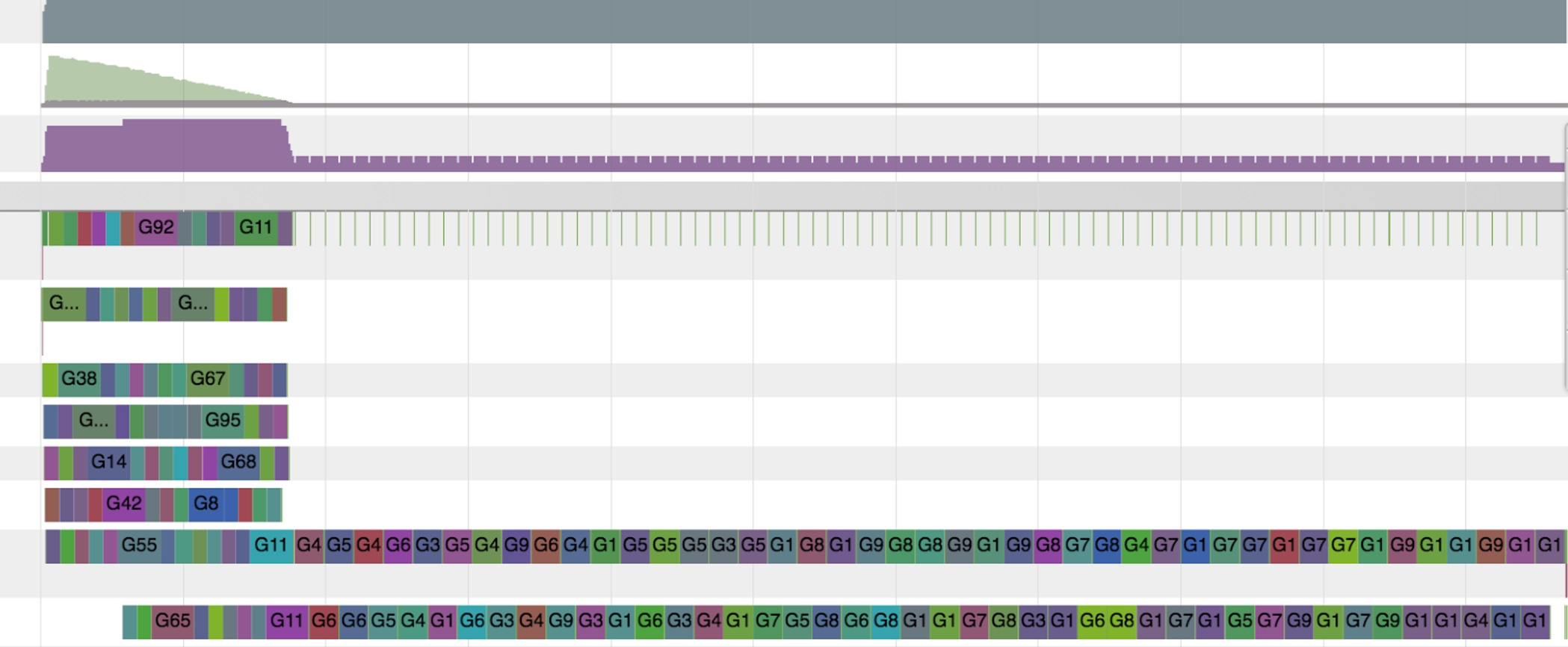
Hier zeigt die Visualisierung durch go tool trace, dass
die Ausführung zunächst gut gestartet ist, dann aber nur noch seriell
arbeitet. Das legt nahe, dass Konkurrenz um eine Sperre für eine gemeinsam
genutzte Ressource aufgetreten ist, wodurch ein Flaschenhals entstand.
Schauen Sie sich unter
go tool trace
an, wie man Ablaufdaten sammelt und analysiert.
GODEBUG
Die Laufzeitumgebung emittiert Ereignisse und weitere Informationen,
wenn die Umgebungsvariable
GODEBUG
entsprechend gesetzt ist:
-
GODEBUG=gctrace=1druckt Ereignisse der Speicherbereinigung bei jedem Sammelschritt, inklusive der Größe des gesammelten Speichers und der Pausendauer. -
GODEBUG=inittrace=1druckt eine Zusammenfassung der Laufzeiten sowie Infos zu Speicherzuteilungen abgeschlossener Paketinitialisierungen. -
GODEBUG=schedtrace=Xdruckt Ereignisse der Zeitplanung alle X Millisekunden.
Die Umgebungsvariable GODEBUG kann auch benutzt werden, um Erweiterungen des Befehlssatzes in der Standardbibliothek und der Laufzeitumgebung zu deaktivieren.
-
GODEBUG=cpu.all=offdeaktiviert alle optionalen Befehlssatzerweiterungen. -
GODEBUG=cpu.extension=offdeaktiviert bestimmte Befehle aus den Befehlssatzeerweiterungen.
extension ist der kleingeschriebene Name der Befehlssatzerweiterung, etwa sse41 oder avx.